在这个金秋,“日日新·商量”又拿了金牌!
今日,中文多模态大模型测评基准SuperCLUE-V发布10月榜单:
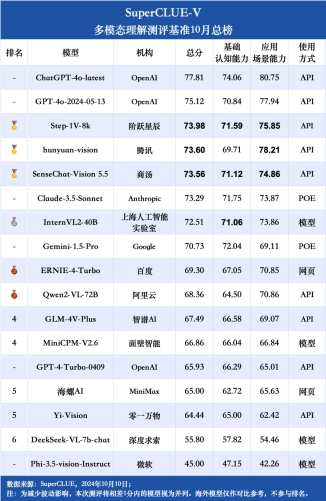
商汤日日新·商量多模态大模型(SenseChat-Vision5.5)凭借多个任务上的出色表现,总得分位列国内大模型第一梯队,智夺金牌。
商量多模态大模型API入口(限时免费!):https://platform.sensenova.cn/doc?path=/model/mllm.md
商汤“商量”注册体验链接:https://chat.sensetime.com/
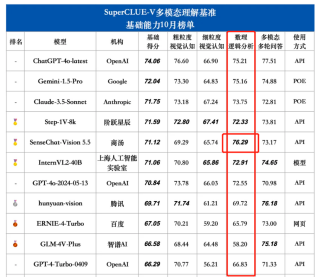
凭借其卓越的多模态基础能力和出色的应用能力,商汤SenseChat-Vision 5.5荣获了总分73.56的高分,并在数理逻辑维度取得第一,体现其强大的推理能力。
SenseChat-Vision5.5基础能力突出,数理逻辑维度超越GPT-4o
本次SuperCLUE-V涵盖了国内外最具代表性的11个开源/闭源多模态理解大模型,聚焦多维度能力评估,包括基础能力和应用能力两个大方向,以开放式问题形式对多模态大模型进行评估,涵盖了8个一级维度30个二级维度。
报告称SenseChat-Vision 5.5在基础能力-数理逻辑推理任务如图表推理、场景推理方面具备领先优势。榜单显示,在数理逻辑分析能力中,SenseChat-Vision 5.5超越国内外所有参评模型包括GPT-4o的最新版本,位列第一。
SuperCLUE-V采用细粒度评估方式,构建专用测评集,每个维度进行细粒度的评估并可以提供详细的反馈信息,以下为SenseChat-Vision 5.5测试案例部分呈现:



目前,多模态大模型能力显著提升,可提供纯语言、多图理解、语音、文生图、拟人、端侧模拟、行业模型等多模态、多版本、强场景Agent形态。
前瞻构造高阶思维逻辑数据,用推理能力增强AI大模型智能
如今,复杂推理成为各模型之间的重要能力壁垒。对于大模型能力的分层,商汤科技董事长兼首席执行官徐立博士此前就提出三层架构(KRE)理论,即:第一层知识(Knowledge),世界知识的全面灌注;第二层推理(Reasoning),理性思维的质变提升;第三层执行(Execution),世界内容的互动变革。
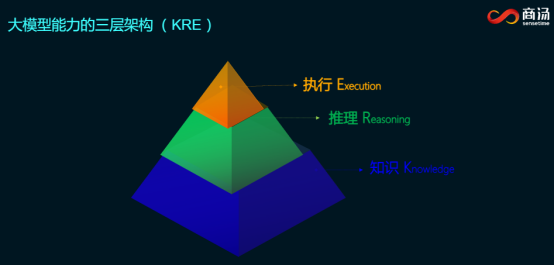
这三层可以组成一个对于世界提供生产力工具模型的完备能力,其中提升基础模型的推理能力是目前人工智能发展的大方向。徐立博士还提出在垂直行业里如何构造高阶思维逻辑的合成数据,也是制胜关键。
今年7月发布的“日日新5.5”大模型体系就创新使用大量使用合成高阶思维链数据,提升推理思维能力,在数理逻辑、英文、指令跟随等方面能力增强明显,2个多月的时间把基模型的能力提升了30%。
未来,商汤科技将继续坚持基础大模型的持续研发与投入,前瞻探索最先进的大模型技术,突破数据与算力的限制,引领大模型的创新与落地。
雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。