8月13日消息,阿里通义大模型继续开源,Qwen2系列开源家族新增音频语言模型Qwen2-Audio。Qwen2-Audio可以不需文本输入,直接进行语音问答,理解并分析用户输入的音频信号,包括人声、自然音、音乐等。该模型在多个权威测评中都显著超越先前的最佳模型。通义团队还同步推出了一套全新的音频理解模型测评基准,相关论文已入选本周正在举办的国际顶会ACL 2024。
声音是人类以及许多生命体用以进行交互和沟通的重要媒介,声音中蕴含丰富的信息,让大模型学会理解各种音频信号,对于通用人工智能的探索至为重要。Qwen2-Audio是通义团队在音频理解模型上的新一步探索,相比前一代模型Qwen-Audio,新版模型有了更强的声音理解能力和更好的指令跟随能力。

Qwen2-Audio可以理解分析音乐
Qwen2-Audio是一款大型音频语言模型(Large Audio-Language Model ,LALM),具备语音聊天和音频分析两种使用模式,前者是指用户可以用语音向模型发出指令,模型无需自动语音识别(ASR)模块就可理解用户输入;后者是指模型能够根据用户指令分析音频信息,包括人类声音、自然声音、音乐或者多种信号混杂的音频。Qwen2-Audio能够自动实现两种模式的切换。Qwen2-Audio支持超过8种语言和方言,如中文、英语、法语、意大利语、西班牙语、德语、日语,粤语。
通义团队同步开源了基础模型 Qwen2-Audio-7B 及其指令跟随版本Qwen2-Audio-7B-Instruct,用户可以通过Hugging Face、魔搭社区ModelScope等下载模型,也可以在魔搭社区“创空间”直接体验模型能力。
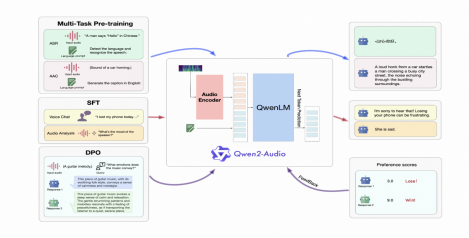
Qwen2-Audio的模型结构与训练方法
根据Qwen2-Audio技术报告,Qwen2-Audio的模型结构包含一个Qwen大语言模型和一个音频编码器。在预训练阶段,依次进行ASR、AAC等多任务预训练以实现音频与语言的对齐,接着通过SFT(监督微调) 强化模型处理下游任务的能力,再通过 DPO(直接偏好优化)方法加强模型与人类偏好的对齐。
研发团队在一系列基准测试集上对模型效果作了评估,包括 LibriSpeech、Common Voice 15、Fleurs、Aishell2、CoVoST2、Meld、Vocalsound 以及通义团队新开发的 AIR-Benchmark基准。在所有任务中,Qwen2-Audio 都显著超越了先前的最佳模型和它的前代 Qwen-Audio,成为新的SOTA模型。
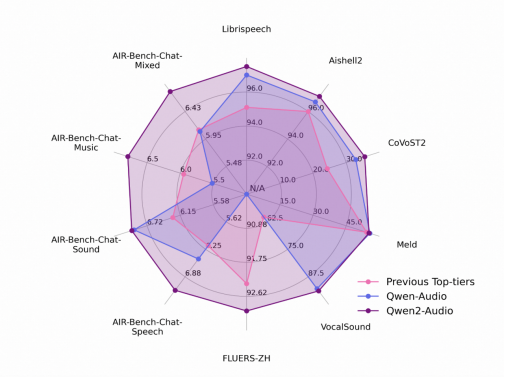
Qwen2-Audio 在多个测评中都显著超越了先前的最佳模型
附:Qwen2-Audio下载或体验地址
魔搭模型页面: https://modelscope.cn/organization/qwen?tab=model
魔搭体验页面: https://www.modelscope.cn/studios/qwen/Qwen2-Audio-Instruct-Demo
GitHub: https://github.com/QwenLM/Qwen2-Audio
Hugging Face:https://huggingface.co/collections/Qwen/qwen2-audio-66b628d694096020e0c52ff6
Qwen2-Audio技术报告: https://arxiv.org/pdf/2407.10759
AIR-Benchmark论文地址: https://arxiv.org/abs/2402.07729
雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。