多模态理解是大模型理解复杂现实世界的关键能力之一。
8月2日,中文多模态大模型SuperCLUE-V基准8月榜单发布,腾讯混元大模型凭借其在多模态理解方面的卓越表现,在众多参评模型中脱颖而出,斩获国内大模型排名第一,稳居卓越领导者象限。

多模态理解,俗称“图生文”,要求模型能准确识别图像元素,理解它们的关系,并生成自然语言描述。这既考验图像识别的精确度,也体现了对场景的全面理解、对细节的深度洞察,考验模型对复杂现实世界的理解力。
本次测评涵盖了国内外最具代表性的12个多模态理解大模型,包含4个海外模型和8个国内代表性多模态模型,评估内容包含基础能力和应用能力两大方向,以开放式问题对多模态大模型进行评估。腾讯混元大模型在多模态基础能力和应用能力方面,获得总分 71.95 的高分,显示出在技术和应用层的综合优势。
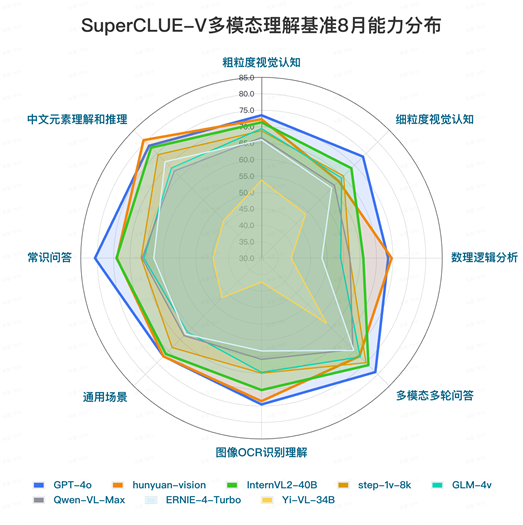
据SuperCLUE官方介绍,评估标准涵盖了理解准确性、回应相关性和推理深度等维度,打分规则结合了自动化定量评分与专家复核,以确保评估的科学性和公正性。
评测结果显示,国内大模型在多模态理解的基础能力方面,已经逼近海外顶尖模型,其中腾讯混元大模型总成绩仅略低于GPT-4o,表现好于CLaude3.5-Sonnet和Gemini-1.5-Pro,显示国产模型在基础能力上的快速迭代。而在应用能力维度上,腾讯混元大模型凭借对中文语境的深刻理解,以及在通用、常识、图像等多领域的综合能力,展现出实际应用的巨大潜力。
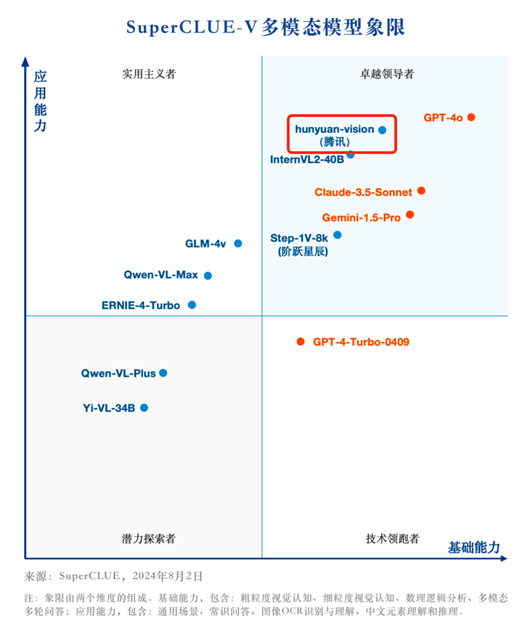
依托腾讯混元大模型的技术底座,AI 原生应用腾讯元宝在发布之初,就具备多模态理解能力,无论是文档截图、人像风景、收银小票,还是任意一张随手拍的照片,元宝都能基于图中内容给出自己的理解和分析。
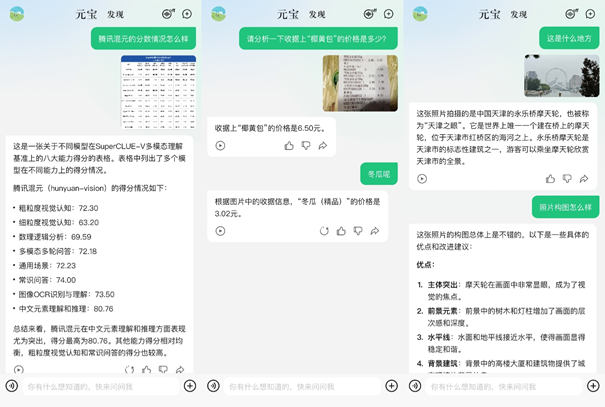
腾讯公司副总裁蒋杰此前表示,对于腾讯混元大模型来说,多模态是一道“必答题”,目前混元大模型正在积极部署从多模态到全模态的技术,用户将很快可在腾讯元宝 App、腾讯内部业务及场景中体验,同时会通过腾讯云向外部应用开放。
目前,腾讯混元大模型已扩展至万亿级参数规模,在国内率先采用混合专家模型(MoE)结构,依托腾讯大语言模型的能力,多模态理解能力不断提升,达到国内领先水平。
雷峰网(公众号:雷峰网)
雷峰网版权文章,未经授权禁止转载。